Efficient Computation of Quantiles over Joins
Nikolaos Tziavelis, Nofar Carmeli, Wolfgang Gatterbauer, Benny Kimelfeld, Mirek Riedewald
Introduces the concept of quantile queries (%JQs) and gives new complexity results:
%JQs ask for the answer at some specified relative position (e.g., 50% for the median)
under some ordering over the answers to a Join Query (JQ).
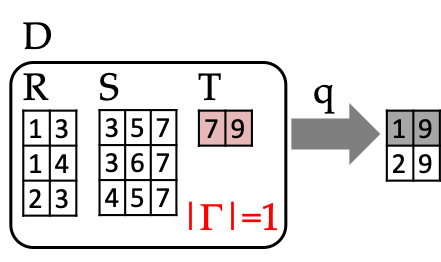
We present efficient algorithms for Quantile Join Queries,
abbreviated as %JQ. A %JQ asks for the answer at some specified
relative position (e.g., 50% for the median)
under some ordering over the answers to a Join Query (JQ).
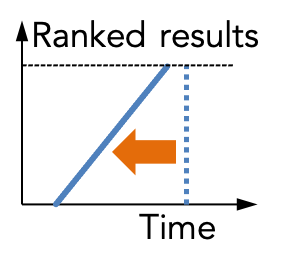
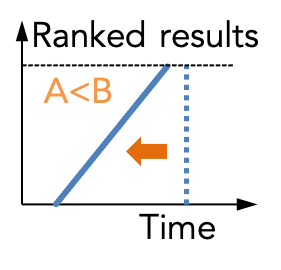
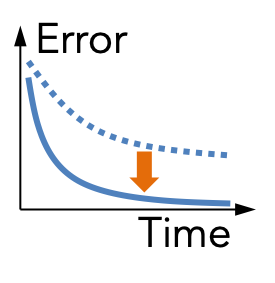
Our goal is to avoid materializing the set of all query answers,
and to achieve quasilinear time in the size of the database,
regardless of the total number of answers.
A recent dichotomy result rules out the existence of such an algorithm for
a general family of queries and orders.
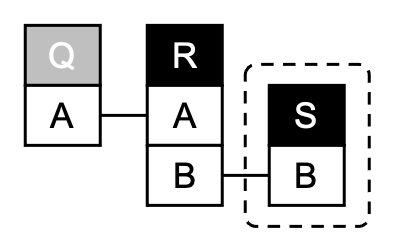
Specifically, for acyclic JQs without self-joins,
the problem becomes intractable
for ordering by sum whenever we are essentially joining more than two relations.
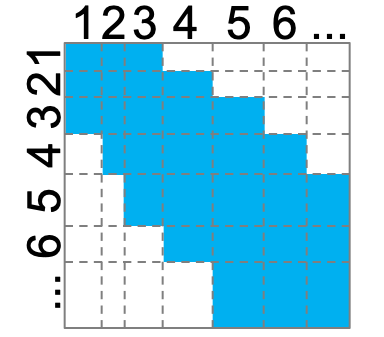
Moreover, even for basic ranking functions beyond sum, such as min or max
over different attributes, it has not been known so far
whether there is any nontrivial tractable %JQ.
In this work, we develop a new approach to solving %JQ and show how this
approach allows not just to recover known results,
but also generalize them and resolve open cases.
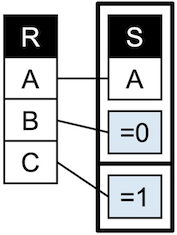
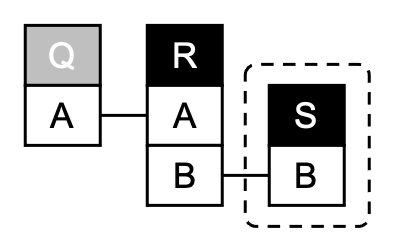
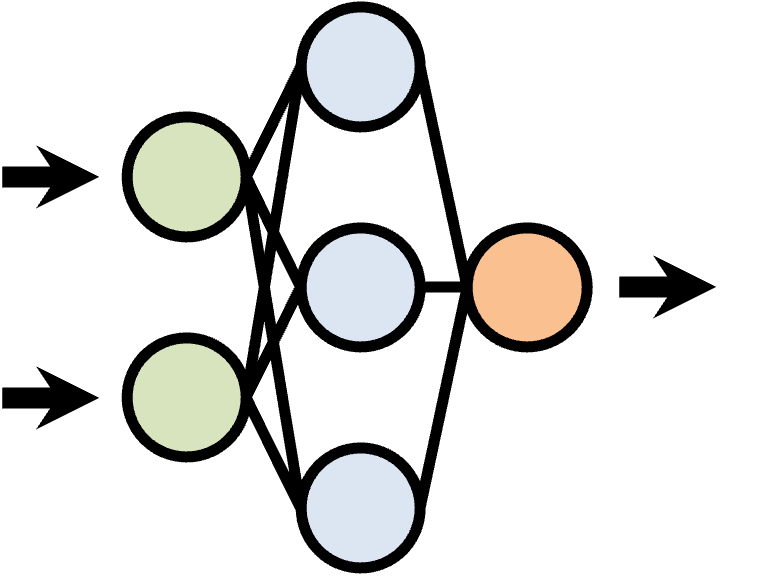
Our solution uses two subroutines:
The first one needs to select what we call a ``pivot answer.''
The second subroutine partitions the space of query answers
according to this pivot, and continues searching in one partition that is
represented as new %JQ over a new database.
For pivot selection, we develop an algorithm that, under mild assumptions of
monotonicity, works for every ranking function.
The second subroutine requires a customized construction for the
specific ranking function at hand.
We show the benefit and generality of our approach by using it to establish several new complexity
results.
First, we prove the tractability of min and max for all acyclic JQs, thereby resolving the above question.
Second, we extend the previous
dichotomy for sum to all partial sums (over all subsets of the attributes).
Third, we handle the intractable cases of sum
by devising a deterministic approximation scheme that applies to every acyclic JQ.


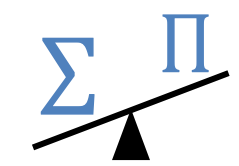

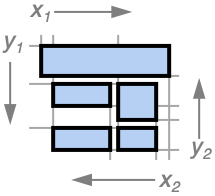
{kind=link}
{kind=link}