Projects
Current projects
|
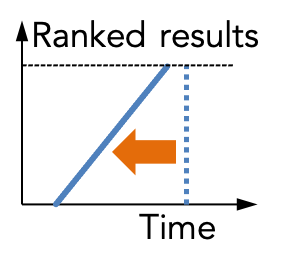
Any-k: Optimal ranked enumeration for Dynamic Programs
Dynamic programming is a very general algorithmic technique for solving an optimization problem by recursively breaking it down into simpler subproblems. But what if you want to enumerate all solutions in decreasing order of optimality instead of simply retrieving the optimal solution? We study the algebraic limits of distributing the ORDER BY operator over the JOIN operator and thereby generalize dynamic programming to ranked enumeration of answers (actually over very general algebraic structures called "selective dioids", which are semirings with an ordering property). The resulting framework is as general as dynamic programming itself, and generalizes seemingly different problems that had been studied in isolation in the past. We call it "any-k" to emphasize the marriage of "anytime algorithms" with "top-k." As a direct application, we apply our theory to the special case of ranked enumeration over conjunctive queries with equi-joins and theta-joins and show that our proof-of-concept implementations beat current database systems by orders of magnitude. See Nikos' talk @ Simons Institute Nov 2023 (32min) |
|
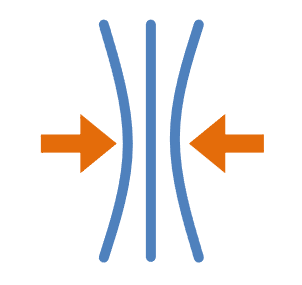
Factorized Knowledge Representation and Reverse Data Management
Given propositional knowledge in explicit form: What computational resources do we need in order to find a representation that is logically equivalent but minimal in size? One concrete problem we are studying is finding the minimal-size factorization of the provenance of database queries. Our formulation allows a complete solution that naturally recovers exact solutions for all known PTIME cases. It also identifies additional queries for which the problem can be solved in PTIME. We make first steps towards a dichotomy of the data complexity of the problem. See Neha's talk @ Simons Institute Nov 2023 (28min) |
|
Algebraic Amplification from Factorized Graph Representations
How can we perform semi-supervised node classification super fast even if we only have very few labeled data points? To answer this question, we have been investigating algebraic properties that allow algorithms to compress data before handing the data over to the learning module. Our approach first creates multiple factorized graph representations (with size independent of the graph) and then performs estimation on these smaller graph summaries. We refer to "algebraic amplification" as the underlying idea of leveraging algebraic properties of an algorithm's update equations in order to amplify sparse signals in data. We show that our estimator is orders of magnitude faster than alternative approaches and that the end-to-end classification accuracy is comparable to using gold-standard compatibilities. This makes it a cheap pre-processing step for any existing label propagation method and removes the current dependence on heuristics. See recent talk @ Simons Institute Nov 2023 (29min) |
|
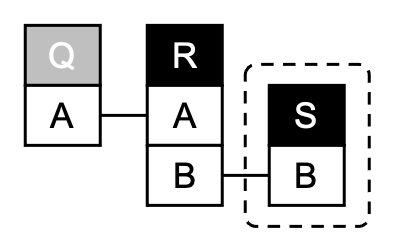
Relational Diagrams for Explaining Relational Query Patterns
Re-use of existing SQL queries is difficult since queries are complex structures and not easily understood. Relational Diagrams (and their precursor QueryVis) are intuitive diagrams that help users understand the meaning of relational queries. They are inspired by the First-Order logic representation of a query and combine succinct features of both tuple and domain relational calculus, thereby providing a minimal yet expressive visual vocabulary. See early vision talk @ VLDB Sept 2011 (19min) |
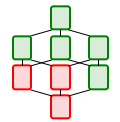
|
Dissociation and Propagation for Approximate Lifted Inference
Evaluating queries over probabilistic databases needs to calculate the reliability of a query and is #P-hard in general. We propose an alternative efficient approach for approximate lifted inference which (i) is always in PTIME for every query and data instance (and even expressible in relational algebra), (ii) always results in a unique and well-defined score in [0,1], (iii) is an upper bound to query reliability and both are identical for safe queries, and (iv) is inspired by widely deployed propagation approaches for ranking in networks, and generalizes those from graphs to hypergraphs. See a short tutorial on how dissociation improves mini-bucket Oct 2016 (21min) |
|
Bootstrapping Virtuous Active Learning cYcles (BOVALY)
We are developing a novel Quiz Item Management System (QIMS) that engages students throughout the semester in a sequence of learning activities. Each of these learning activities fosters critical thinking, and together they lead to knowledge artifacts in the form of quiz items. These artifacts go through cycles of creation, improvements, selections, and deduplications, and they lead to re-usable learning artifacts with known provenance and item response characteristics. The approach thus addresses 5 important challenges for technology-enhanced learning (e.g., MOOCs): 1. Continuous practice and assessment 2. Practice of "generative" skills, 3. "Auto-calibrated" peer evaluation, 4. Re-usable learning artifacts, and 5. Optimal use of instructors' time. See a short vision talk Sept 2014 (4min), and slides from Northeastern's Conference for Advancing Evidence-Based Learning (CABL) 2019 |

|
Table-As-Query as Semi-Supervised Table Alignment
Given a table provided by a user and a large repository of tables of unknown accuracy and unknown relevance: How can we best complete the seed table with information from the repository? Our focus is on both table discovery (finding a set of alignable tables), as well as determining the best way to integrate (or align) the tables from the repository with the query table. In this new paradigm called "table-as-query", a seed (or query) table provided by the user is enough, and the user does not need to know a priori which attributes of the tables in a repository are best aligned. |
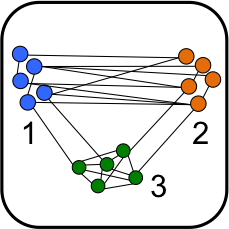
|
Semi-supervised Learning with Heterophily (SSLH)
SSLH is a family of linear inference algorithms that generalize existing graph-based label propagation algorithms by allowing them to propagate generalized assumptions about "attraction" or "compatibility" between classes of neighboring nodes (in particular those that involve heterophily between nodes where "opposites attract"). Importantly, this framework allows us to reduce the problem of estimating the relative compatibility between nodes from partially labeled graphs, into a simple optimization problem. The result is a very fast algorithm that (despite its simplicity) is surprisingly effective. |
Past projects

|
Causality in databases: helping users understand unexpected query results
When queries return unexpected results, users are interested in explanations for what they see. Recently, the database community has proposed various notions of provenance for query results, such as why or where provenance, and very recently, explanations for non-answers. We propose to unify and extend existing approaches for provenance and missing query result explanations ("positive and negative provenance") into one single framework, namely that of understanding causal relationships in databases. |

|
BeliefDB: managing conflicting beliefs inside a standard DBMS
Data management is becoming increasingly social. Questions arise about how to best model inconsistent and changing opinions in a community of users inside a DBMS. First, we propose an annotation semantic based on modal logic; this allows users to engage in a structured discussion. Second, we propose a principled solution to the automated conflict resolution problem. While based on the certain tuples of all stable models of a logic program, our algorithm is still in PTIME. |
|
VENTex (Visualized Element Nodes Table Extraction)
Web tables contain a vast amount of semantically explicit information, which makes them a worthwhile target for automatic information extraction and knowledge acquisition from the Web. However, extracting and interpreting web tables is difficult, because of the variety in which tables can be encoded in HTML and style sheets. Our approach, called "VENTex", can extract arbitrary web tables by focusing on table representations in the "Visual Web" instead of the "Syntactic Web" as used by previous approaches. |

|
Unique Recall: modeling the limits of knowledge acquisition from redundant data
Often in life, 20% of effort can achieve roughly 80% of the desired effects. Interestingly, this does not hold in the context of web information extraction. We develop an analytic model for information acquisition from redundant data (in the limit of infinitely large data), and use it to derive a new 40-20 rule (crawling 20% of the Web will help us learn less than 40% of its content). We further describe a new family of power law functions that remain invariant under sampling, and use their properties to give a second rule of thumb. |
|
CQMS (Collaborative Query Management System)
While modern database management systems (DBMSs) provide sophisticated tools for managing data, tools for managing queries over these data have remained relatively primitive. As analysts today share and explore increasingly large volumes of data, they need assistance for repeatedly issuing their queries. This project develops the essential techniques for a Collaborative Query Management System (CQMS) which provides new capabilities ranging from query browsing to automatic query recommendations. |

|
Economics of deregulated electricity markets
We revisit commonly accepted assumptions about the economics of deregulated electricity markets. First, we disprove that, in theory and under the condition of perfect information, decentralized and centralized unit commitment would lead to the same quantities of power traded and the same optimal social welfare. Second, we show that a generator owner's optimum bid sequence for an auction market is generally above marginal cost, even where absolutely no abuse of market power is involved. |
|
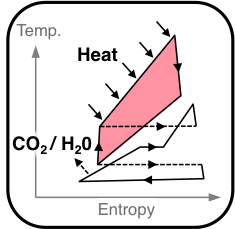
Graz Cycle: a zero emission power cycle of highest efficiency
The Graz Cycle is a thermodynamic combustion cycle that allows to retain and capture CO2 emissions stemming from combustion processes. It burns fossil fuels with pure oxygen which enables the cost-effective separation of the combustion of CO2 through condensation. The efforts for the oxygen supply in an air separation plant are partly compensated by cycle efficiencies far higher than 65%. The combined efficiency is equal in thermodynamic performance to any other proposal in the field of Carbon Capture and Storage (CCS). |